K-Means and DBSCAN from scratch [Julia] - 1/3
This post introduce the ClusterAnalysis.jl package that I and eliascarv built from scratch using only the Julia Language. We implement K-Means and DBSCAN clustering algorithms and achieved a performance superior to the same Scikit-Learn algorithms.
The package is mostly a learning experiment, but the package were also built and documented to be used by anyone, Plug-and-Play. Just input your data as an Array or a Tables.jl type (like DataFrames.jl), then start training your clusters algorithms and analyze your results.
Documentation: https://augustocl.github.io/ClusterAnalysis.jl/
To install the package just follow this commands in your Julia REPL.
# press ] to enter in Pkg REPL mode.
julia> ]
pkg> add ClusterAnalysisA quick example
# load packages
using CSV, DataFrames
using StatsPlots
using ClusterAnalysis
# load data from github repo
df = CSV.read("algo_overview/blob_data.csv", DataFrame, drop=[1]);
X = df[:,1:2];
y = df[:,end];
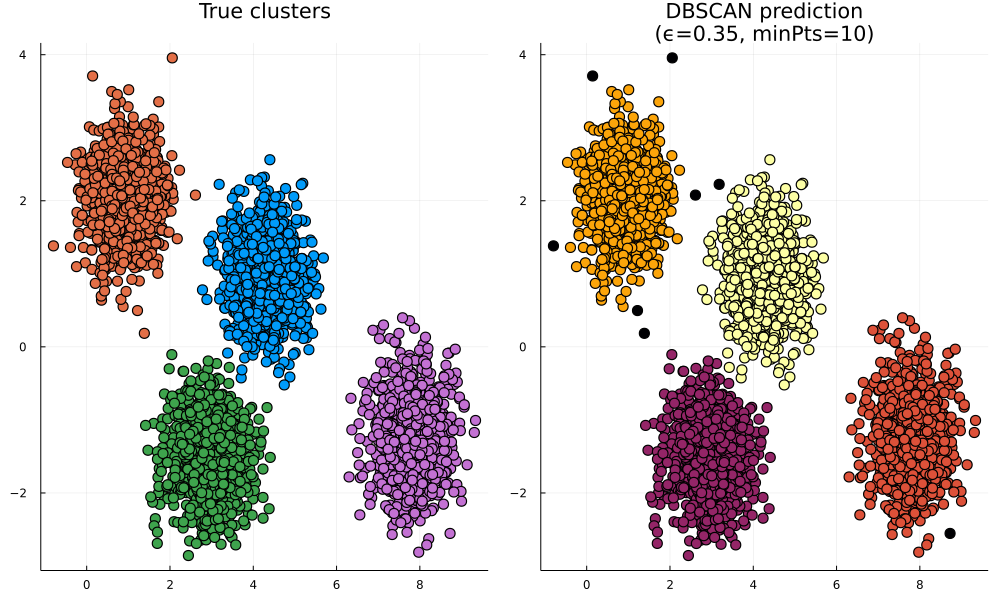
# dbscan model
ϵ = 0.35;
min_pts = 10;
m = dbscan(X, ϵ, min_pts);
# plot
gr(size=(1000,600))
p1 = scatter(X[:,1], X[:,2], group=y,
leg=false,
ms=6,
title="True clusters");
p2 = scatter(X[:,1], X[:,2], zcolor=m.labels,
leg=false,
ms=6,
title="DBSCAN prediction\n(ϵ=$(ϵ), minPts=$(min_pts))");
plot(p1, p2, layout=2)
Algorithm’s Overview
That section is presented in github repo or in the “Algorithms” section in documentation, which succintly explains how each algorithm works.
The Algorithm’s Overview of K-Means, by example, has a lot of images, gifs and a pseudocode to help the user understand the source-code.
I really suggest you to read the Algorithm’s Overview Section along with the source code for a better understanding of the algorithm.
Benchmark
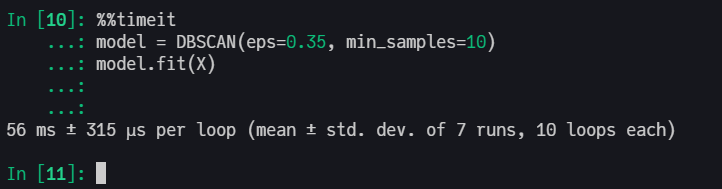
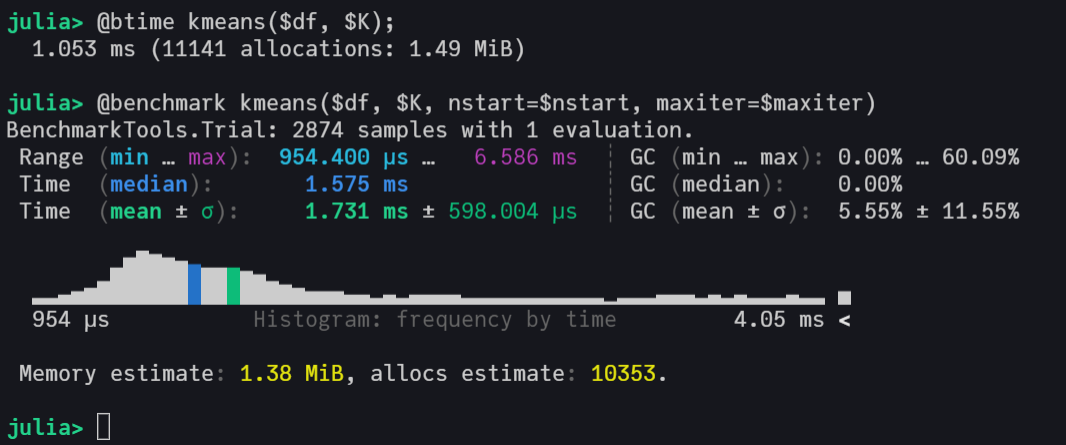
This implementation has an excellent computational performance, being faster than Scikit-Learn’s KMeans and DBSCAN.
Here is an example with K-Means, but we also have the same benchmark in DBSCAN overview section.
Scikit-Learn with C in backend
ClusterAnalysis.jl in Pure Julia
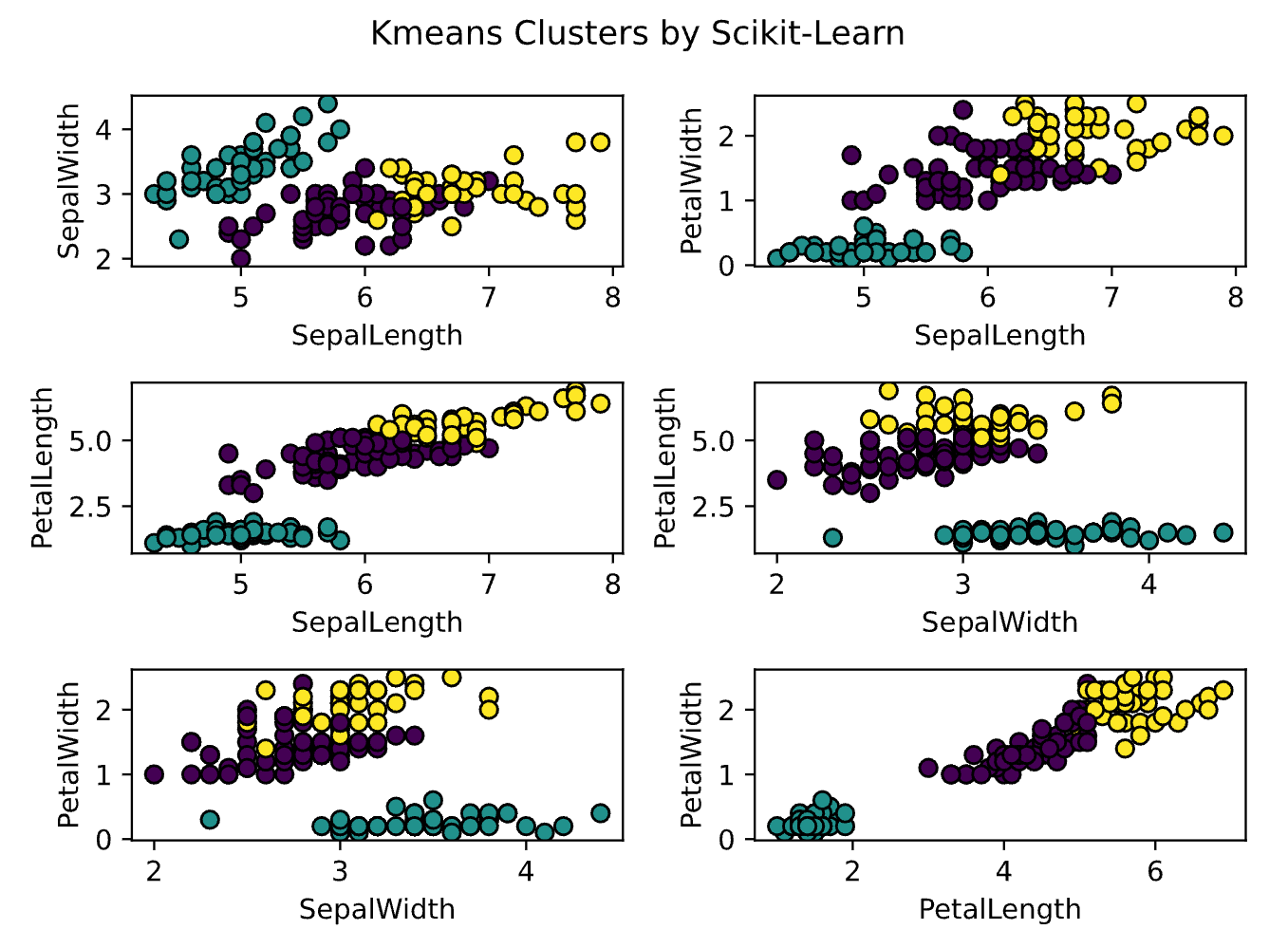
Here is another plot comparing results from Julia to SKlearn.
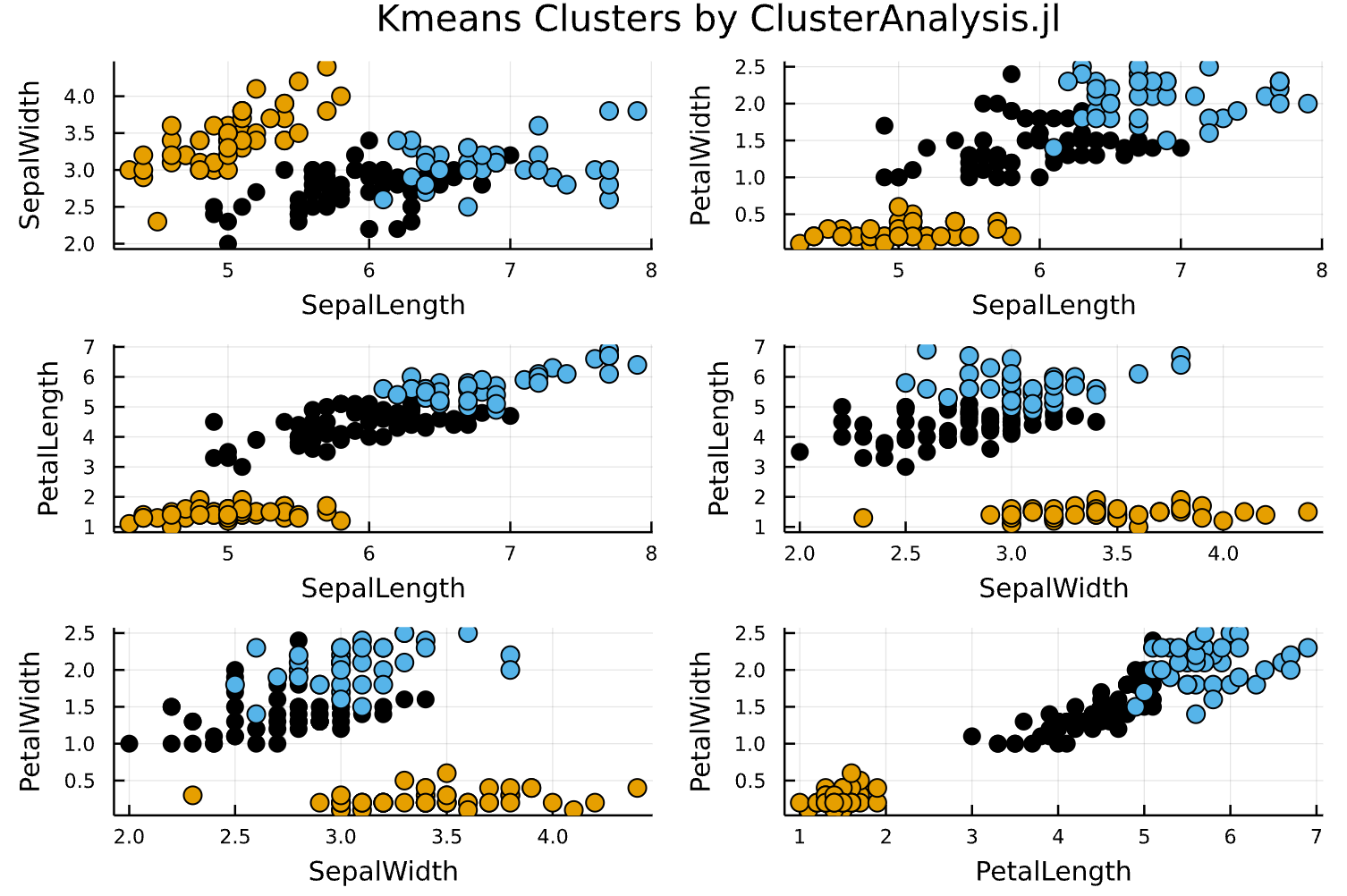
In the next posts I will detail K-Means and DBSCAN algorithms produced in this package, explaining all the logic used in the construction of the source code. For now, check the Algorithm’s Overview and use the package in your clusters analysis. If you have any suggestion about the pkg, feel free to contact me in github.